
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- spring
- facade pattern
- 자바8인액션
- Design Pattern
- head first
- CQRS
- Java 8 in action
- 자바의 신
- Java
- Clean Code
- 클린코드
- Java8 in action
- 패스트캠퍼스
- Java in action
- spring Batch
- ddd
- 디자인 패턴
- SERVLET
- Stream
- 자바8
- Java8
- 스트림
- domain
- web
- Template Method Pattern
- Was
- 자바
- spring boot
- jsp
- AWS101
- Today
- Total
주난v 개발 성장기
[자바 8인 액션] 7장. 병렬 데이터 처리와 성능 본문
병렬 스트림
- parallelStream을 호출하면 병렬 스트림 생성
- 각각의 스레드에서 처리할 수 있도록 스트림 요소를 여러 청크로 분할한 스트림

순차 스트림을 병렬 스트림으로 변환하기
- 순차 스트림에 parallel 메서드를 호출하면 리듀싱 연산이 병렬로 처리
병렬 스트림에서 스레드 풀 설정
- 병렬 스트림은 내부적으로 ForkJoinPool 사용
-프로세서 수, Runtime.getRuntime().availableProcessors()가 반환하는 값에 상응하는 스레드를 가짐.
- 전역 설정이므로, 모든 병렬 연산에 영향을 준다. 특정한 값을 따로 지정할 수는 없다.
스트림의 성능 측정
- (예제 7-1) 참고
- sequential sum :97ms, for : 2ms, parallel : 164ms
병렬 처리가 순차 처리보다 속도가 느리다..?
- iterate가 박싱된 객체를 생성하므로, 이를 다시 언박싱하는 과정이 필요했다.
- iterate는 병렬로 실행할 수 있도록 독립적인 청크로 분할하기가 어렵다.
더 특화된 메서드 사용
- LongStream.rangeClosed는 기본형을 직접 사용하므로 박싱과 언박싱 오버헤드가 사라진다.
- rangeClosed로 범위를 생산할 수 있다.
--> 이 결과 iterate 팩토리 메서드 때 보다 속도가 빠르다.
이유는, 특화되지 않은 스트림을 처리할 때는 오토박싱, 언박싱등의 오버헤드를 수반한다.
* 병렬화는 스트림을 재귀적으로 분할해야 하고, 각 서브 스트림을 서로 다른 스레드의 리듀싱 연산으로 할당하고, 이를 하나의 결과로 합쳐야 한다.
병렬 스트림은 절대 공유된 상태를 바꾸는 케이스에서는 사용하면 안된다.
병렬 스트림 효과적으로 사용하기
병렬 스트림의 사용기준은 '데이터의 양' 같은 걸로는 적합하지 않다.
-
확신이 서지 않는다면 직접 측정해라. 순차를 병렬로 바꾸기에는 쉽지만, 바꾼다고 능사는 아니다.
-
박싱을 주의해라. 언박싱 및 오토박싱은 성능을 저하시킬 수 있다. -> 기본형 특화 스트림
-
limit, findFirst 같은 케이스는 병렬로 처리할 때 비싼 비용을 치러야 한다. 성능 저하
-
소량의 데이터에서는 병렬 과정에서 생기는 부가 비용을 상쇄할 만큼의 이득을 얻을 수 없다.
-
ArrayList가 LinkedList보다 효율적이다. (LinkedList는 모든 요소를 탐색해서 분할해야 한다.)

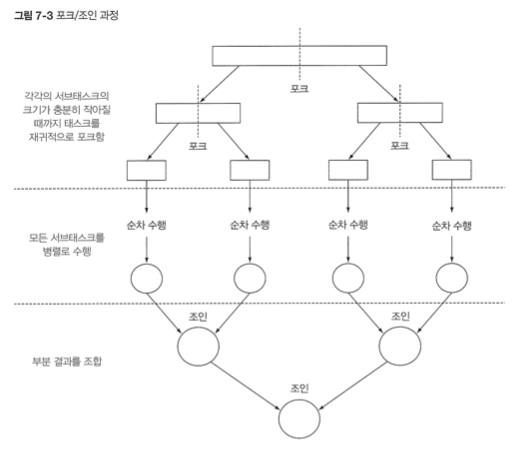
포크 / 조인 프레임워크
- 병렬화할 수 있는 작업을 재귀적으로 작은 작업으로 분할한 다음에 서브태스크 각각의 결과를 합쳐서 전체 결과를 만든다.
- 분할 후 정복
[예제 7-2]
- extends RecursiveTask
- THRESHOLD 변수를 기준으로, 값이 크면 왼쪽 / 오른쪽 task 분할
- 왼쪽 compute + 오른쪽 compute
일반적으로 애플리케이션에서는 둘 이상의 ForkJoinPool을 사용하지 않는다.
필요한 곳에서 언제든 가져다 쓸 수 있도록 한 번만 인스턴스화해서 정적 필드에 '싱클턴'으로 저장한다.

작업 훔치기
- 분할 기법이 효율적이지 않았을 수도 있고 아니면 예기치 않게 디스크 접근 속도가 저하되거나 지연이 생길 수 있다.
-> 포크 / 조인 프레임워크에서는 "작업 훔치기" 기법이 존재
각각의 스레드는 작업이 끝날때마다 큐의 헤드에서 다른 태스크를 가져와서 작업을 처리
이 때, 작업을 빨리 처리한 스레드가 다른 스레드 큐의 꼬리에서 작업을 훔쳐오고, 모든 테스트가 작업이 끝날때까지 반복한다.
따라서 task의 크기를 작게 나누어야 작업자 스레드 간의 작업부하를 비슷한 수준으로 유지할 수 있다.
Spliterator
'분할 할 수 있는 반복자'
-> iterator처럼 소스의 요소 탐색 기능을 제공한다. 차별점은 병렬 작업에 특화되어 있다.
public interface Spliterator<T> {
boolean tryAdvance(Consumer<? super T> action);
Spliterator<T> trySplit();
long estimateSize();
int characteristics();
}
1. tryAdvance - 요소를 하나씩 순차적으로 소비하면서 탐색해야 할 요소가 남았다면 true
2. trySplit - Spliterator의 일부 요소를 분할해서 두 번째 Spliterator의todtjd
3. estimateSize - 메서드로 탐색할 요소 수 (요소 수가 정확하진 않더라도 제공된 값을 이용해서 쉽고, 공평하게 분할 가능)
분할 과정
- trySplit의 결과가 null이면 재귀 분할 과정 종료, null이 아니면 계속 반복
- Characteristics 메서드는 Spliterator 자체의 특성 집합을 포함하는 int 반환
요약
-
내부 반복을 이용하면 명시적으로 다른 스레드를 사용하지 않고도 스트림을 병렬로 처리할 수 있다.
-
병렬이 항상 빠른 것은 아니니 속도 측정을 해봐라.
-
일반적으로, 처리할 데이터가 많거나 요소를 처리하는 데 오랜 시간이 걸릴 때 병렬 스트림을 사용하면 성능을 높일 수 있다.
-
포크 / 조인 프레임워크에서는 task를 작은 task로 분할한 다음에 각각의 스레드로 실행하여 결과를 합쳐서 최종 결과를 생산한다.
-
Spliterator는 탐색하려는 데이터를 포함하는 스트림을 어떻게 병렬화할 것인지 정의한다.
'개발 성장기 > JAVA' 카테고리의 다른 글
| [자바 8인 액션] 6장. 스트림으로 데이터 수집 (0) | 2020.07.21 |
|---|---|
| [자바 8인 액션] 5장. 스트림 활용 (0) | 2020.07.15 |
| [자바 8인 액션] 4장. 스트림 소개 (0) | 2020.07.05 |
| [자바 8인 액션] 3장. 람다 표현식 (0) | 2020.07.01 |
| [자바 8 인 액션] 2장. 동작 파라미터화 코드 전달 (0) | 2020.06.17 |
